Fault handling in a Structured Process in Oracle Integration (OIC) is not always trivial, especially not when you have specific requirements for it. This article describes how such a challenge can be approached by means of the Custom Fault Handling pattern.
In the following first the out-of-the-box fault handling using the fault policy is described. Some arguments are given why this might not properly tackle your situation, but disabling it is also not the proper option. After that it is described how implementing custom fault handling can provide a good alternative.
Handling with Default Fault Policy
When activating a Structured Process in OIC the default option is Use Fault Policies with the Default checkbox checked.

This implies that Structured Process handles a fault with invoking an Integration (or Web Service or REST API, in the remainder all referred to as “service”) by doing 2 retries in a row with exponential back-off (1st retry after 5 seconds, 2nd retry 10 seconds after the 1st retry).
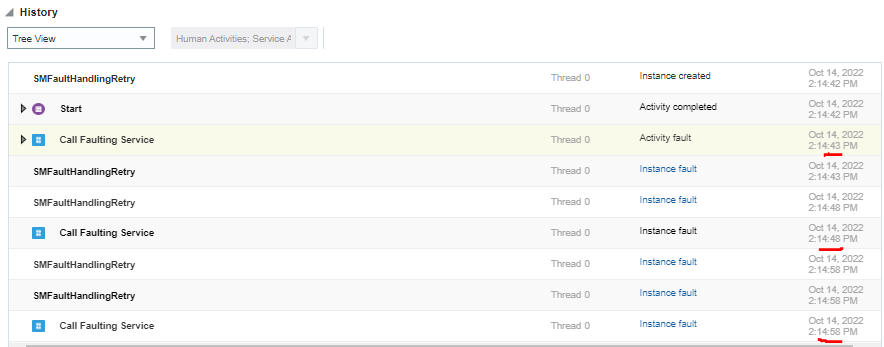
This is probably not what you want, for one or more of the following reasons:
- The cause of a fault probably makes these automatic retries not useful, as it is unlikely to succeed on such a short notice. Think about the situation where a service is temporarily not available, the credentials or authorization are not properly configured, or there is something wrong with the configuration of the target application.
- In case of a service that is not available, retries on a short notice may add insult to injury when the root cause is an overload of service.
- In case of wrong credentials, the collateral damage could be that the used account gets locked out.
- When the services creates or updates data in a SaaS application it the call probably is not idempotent (that is cannot be called more than once with the same result), which makes any retry before investigation “dangerous”.
In practically all cases I therefore ended up with activating the Process Application with fault policies turned off which – considering it to be the default - is easy enough to forget, by the way.
Handling Without Default Fault Policy
With fault policies turned off the process stops after running into a fault. The fault can then be investigated, and handled from the Workspace using one of 4 options:
- Abort: this aborts the process instance and all associated instances (like a parent process in the same application which started the culprit instance).
- Retry: this retries the invoke to the service.
- Alter Flow & Suspend: this gives the administrator the option to move the token of the instance somewhere else in the flow, for example to some previous activity (which would then make the service call happening again) or some later activity while ignoring the fault.
- Cancel: this aborts the culprit process instance but will leave all other related instances running.
This article is not to guide you on how to use any of these options (for that you are referred to the section Monitor and Adjust Process of the online documentation). What I do want to point out though, is that this way of handling faults might also not be what you are looking for, for one or more of the following reasons:
- It does not support advanced fault policies, like:
- Retries after minutes or hours, with the last one outside the time-window after which it should work as per its SLA.
- Different ways of handling, depending on the service or nature of the fault. For example, in case of a timeout an automatic retry may make sense but not in case of a security or data issue.
- Although advanced enough to handle practically any fault (you can not only move the token but also change the payload of the instance), Alter Flow might be too advanced for the administrator, especially when not proficient with BPMN.
- It does not support involving a business user, which might be needed in case of a data issue. For example, think of a situation where submitting an order fails because the customer has not yet been validated by the business.
When the before is applicable to your situation you probably have a need for custom fault handling. The following describes how that can look like.
Custom Fault Handling
The core of the custom fault handling solution is a 3-step process:
- The process catches the fault and forwards it to a generic fault handling process.
- In the fault handling process a fault policy is applied or the fault is handled by an administrator or business user. The outcome of the fault handling process is an action with a value which is one of “abort”, “retry”, or “continue”, which is passed back to the process instance having the issue.
- The process instance acts upon the returned action. What that is, depends on the nature of the process but typically is one of:
- Stop processing (abort)
- Retry the service call (retry)
- Ignore the fault and move on (continue)
The following picture shows how the process instance catches the error and forwards it to the fault handling process using a Send activity. After the Send the fault handling process determines what should happen next, which is received by the process instance using a Receive activity.
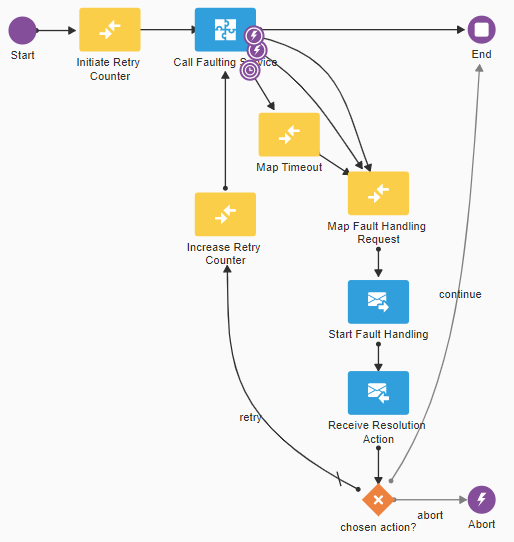
This process is implemented as a Reusable Subprocess which is invoked by a parent process using a Call activity. The pattern for invoking a service and catching the errors is the same for each service, except for the type of errors to catch and the flows coming out of the chosen action? gateway. The first depends on the nature of the service (and for example is different for SOAP services than for REST API’s) while the applicable flows depend on the viable options in the context of the parent process.
The service call has 2 Boundary Error events, one for the BindingFault and one for the RemoteFault, It also has a Boundary Timer event to catch a timeout. You could use a mechanism that sets a configurable amount of time to the timer, depending on the service provider.
In the Map Fault Handling Request activity sufficient information is mapped to the request of the fault handling process so that it can apply the proper fault policy or help the administrator or end user to understand the nature of the fault. With the Start Fault Handling the fault handling process is started while the errored process instances waits for what to do next in the Receive Resolution Action activity.
In case of “retry”, a retry counter is increased so that a next time the fault handling process “knows” how many times the service has already been invoked. In case of “abort” an Error End event is thrown, which must be captured by the parent process.
The following picture shows how the generic fault handling process could look like.

The Apply Faut Handling Policies activity is a call to some business rule which determines what the fault handling process should do next:
- Return “retry” to the process instance after a (configurable) amount of time.
- Forward the fault to a business user by means of a Human Task
- Send the fault to an administrator by means of a Human Task. The administrator can also forward the fault to a business user.
The fault policy can be implemented by a Decision Service or some other component which behaves like a business rule engine. That means that the component does not act upon the fault itself, but instead returns some outcome which determines the next step of the fault handling process.
The following gives an example of the implementation of a fault policy using the OIC Decision Service (many thanks to Marcel van der Glind who inspired me with his example).

As you can see the action which determines the next step is depending on the name and version of the service, the fault code and the number of retries already done. In this example you can see that in case of a fault code with value 500, the Faulting Service version 1.0 should be retried after 5 and then after 10 seconds (for the sake of example and due to my lack of my patience, the same as the default fault policy of OIC itself) and - after the second attempt failed - then forwarded to the administrator. In case of a fault code other than 500 it should go straight to the administrator, as is the case for any other service or version.
After automatic or manual determination of the action, the fault handling process returns that back to the culprit process instance by means of the End event, which is a callback to the afore mentioned Receive Resolution Action Receive activity.
As explained, the fault handling process is generic and therefore implemented in a Process Application of its own. To minimize the risk of an exception happening in the exception handler itself, it should be kept as simple as possible and not unnecessarily never depend on any other component which on its turn might fail.
Assuming that the administrator will be given access to the Workspace, you should consider using an out-of-the-box web form to implement it. Web forms are somewhat limited so you cannot implement logic that would hide buttons for actions that are not applicable. Hence the valid action? loop back in the flow. As far as the Human Task for business users is concerned, you probably need to implement that using a more advance UI technology like Visual Builder.
