This article discusses how fault handling in Integrations
works for the Oracle Integration Cloud, and some best practices on how to use
it, including consuming Integrations in Structured Processes.
Updated on August 6 2020 after discovering that in the explanation of Fault Return parts of the text were duplicated while others were missing.
Updated on April 23 2021 since OIC now provides access to the specific elements of each individual fault, making it better to have an individual Fault Handler for each one of them instead of using the Default Fault handler.
As this is
a lengthy article I will start with the conclusion including what I consider to
be the best practices, so if you trust me you can stop right there 😉
Best
practice is to always put an Invoke activity
in a Scope. Implement a Fault Handler for each individual fault that may be raised within the scope. In the
Fault Handler use the Fault Return
option to throw a fault coming from the back-end service to the consumer of the
Integration for three reasons:
- It gives you maximum control over
the way the fault is returned to the consumer. For example, only with Fault
Return will you be able to return the HTTP 4xx or 5xx status code from the back-end
service as-is to the consumer of a REST Integration.
- With that it allows you to wrap the
fault from the back-end services in one single type of fault thrown to the
consumer, making fault handling by the consumer as simple as possible. For
example, in case of a modeled SOAP Fault returned to a Structured Process, it
now suffices to add one single Boundary Error Event for the modeled fault to
handle all business faults in the process.
- On the Monitoring tab the integration
instance that handled the fault from the back-end service is itself flagged as “Succeeded”
(instead of “Errored”), which strictly speaking is correct as the integration
did what it had to do (don’t blame the messenger). After all, the actual fault
happened in the back-end service. So instead of unnecessarily alarming the
operator of OIC (which caused no issue), Operations should look at either the
consumer or the back-end service to find out what went wrong.
In other
words, Fault Return is the easiest way to return faults thrown by the back-end
service(s) in a consistent way. This is can be very convenient for your
consumer.
Next sections will discuss several aspects of fault handing and will show you the background that motivates these best practices.
Fault Types
A distinction can be made between business faults and system faults where the first refers to a fault explicitly thrown from the business logic. In case of SOAP, business faults are called modeled faults as they are modeled in the WSDL as a "fault" element. In case of REST there is a similarity with the difference between HTTP 4xx client errors and 5xx server errors, although it cannot be compared 100%. For reasons of completeness: according to the W3C specifications a SOAP fault must be sent with an HTTP 500 error code.
For the remainder I will use the term modeled fault for both the modeled SOAP fault as well as any REST HTTP 4xx error code, and system fault for the un-modeled SOAP fault and any REST HTTP 5xx status code.
Modeled faults normally come from a back-end service, for example to indicate that it has been called with invalid data (like order with status “paid” cannot be changed). In some cases, you may want to add a modeled fault to the WSDL of the SOAP Integration itself. As discussed hereafter, you do so when implementing fault encapsulation.
System faults are technical faults that for example occur when the back-end service is not available or times out, or when a mapping fails due to a programming error. System faults therefore can come from both the back-end service or are raised by the integration itself.
Fault Handlers
In an Integration a fault is handled in what is called a Fault Handler. At the top level there is a specific fault handler, called Global Fault. As you have no information about the context of the fault other than the parameters and request of the integration, the Global Fault is typically used as a “last resort” only.
A Fault Handler at a lower level is always part of a Scope. To every Scope you can add a Default (Fault) Handler. When the invoked SOAP service exposes one or more modeled faults, you can also add a Fault Handler for every individual type of SOAP fault. The Default Handler is like a “catch all” meaning that if you don’t have a handler configured for a specific fault, the Default Handler will be used. In case of a REST services, the faults to handle are the APIInvocationErrors.
 |
Fault Handlers per type of fault
|
| Best practice | To have more control over and specifically access to the context of the fault, you best put an Invoke activity in a Scope to which you can add a Fault Handler when needed. In case of complex Integrations with many invokes, another advantage of using Scopes is that you can collapse them to get a clearer view of the overall logic of the flow of the integration. |
As is explained hereafter, you cannot pass on the original fault as thrown by the back-end service. It will always be wrapped in some other fault. Therefore:
| Best practice | Use a Fault Handler for each individual fault that can be thrown in the scope, as this gives you the most specific information about the fault. |
Ways to Throw Faults
There are 4 ways to configure how an integration throws a fault:
- Do nothing
- Rethrow Fault
- Throw New Fault
- Fault Return
For the last three ways you must a Scope with a Fault Handler which will throw the fault to the higher scope. Only the Throw New Fault is available in the Global Fault handler. All four ways to handle faults are discussed hereafter.
Do Nothing
Obviously the simplest way to handle a fault. Applicable when you don’t have any requirement to handle any fault in a special way. You just let it happen and in case of a synchronous integration let it return to the consumer. On the Monitoring tab the Integration will appear as having failed.
 |
No handling
|
Be aware that it is not the actual fault as thrown by the back-end service that is returned. For example, in case the REST back-end service throws a HTTP 404 Not Found, a REST Integration will throw a HTTP 500 Internal Server Error with the actual fault code (404) “hidden” in the errorDetails.title.
As there is no strict standard for it, different back-end systems may have significant differences in the way they throw faults, using different (names of) elements, providing a different level of detail. For this reason, in case of a SOAP fault a SOAP Integration will have the original fault details wrapped in CDATA, as shown below. More on this hereafter.
The following two pictures show the original fault and how OIC is returning that:
 |
Original fault from back-end service
|
 |
| Fault rethrown by Integration |
Rethrow Fault
In this
case the fault is thrown to the higher scope without modification. If there is
no higher scope, then in case of a synchronous integration the consumer will
get the fault as-is and with that the result is the same as when you did
nothing. On the Monitoring tab the Integration will appear as having failed.
 |
| Rethrow Fault |
As
with the Do Nothing scenario, it is
not the actual fault as thrown by the back-end service that is returned. Instead
the original fault is wrapped in CDATA.
Use Cases: You
use Rethrow Fault when you need to do some steps before raising the fault, like
populating a log message (as shown before) or sending an email, but you have no
need for a specific way of handling the fault otherwise.
Throw New Fault
As the name already suggests with New Fault you throw a new, other fault than the one you caught.
This
will give you the opportunity to configure the values of the
errorDetails sub-elements. You can now map a “code”, “reason” and
“details” to the new fault but be aware that these will still end up in
CDATA in the "title" element of the fault returned, like the “New
Fault Code” that has been mapped to “code” in the example below:
 |
| Throw New Fault |
Throw New Fault will give you the opportunity to configure the values of the
errorDetails sub-elements. You can now map a “code”, “reason” and
“details” to the new fault but be aware that these will still end up in
CDATA in the "title" element of the fault returned, like the “New
Fault Code” that has been mapped to “code” in the example below:
 |
| New SOAP fault |
In case of a REST service, the fault is returned as a HTTP 500 Internal Server Error though (not using the value of the "code" element of the New Fault), and on the Monitoring tab the Integration will appear as having failed.
In the example below the back-end REST service threw a HTTP 404. I could have introspected the original fault to find the 404 and then map it to the “code” element, but that would still have ended up where it now reads “New Fault Code” and not in the “errorCode” element at the top (which will be a 500).
 |
New REST Fault
|
Use Cases: As with Rethrow Fault, using Throw New Fault gives you the opportunity to do some steps before raising the fault, but now you can also make the fault a bit clearer to the consumer or easier to handle by manipulating the errorDetails. For example, you can put some special characters around the original fault code to support easy fetching it in an expression.
On its turn you can you can then introspect the "title" element in the higher scope to look up the original fault code, and let it handle one fault differently than another. You could start an alternative flow for one, while the other one is returned to the consumer. For example, in case the back-end create service returns a duplicate error you can invoke the update service instead.
Fault Return
In case of a SOAP service, for the Fault Return option to be available you need to use a Trigger Connection based on a WSDL with a modeled fault, which will take a bit more effort than for the other options.
The Fault Return is like the fancy sibling of the Throw New Fault as it offers you the same benefits but gives you much more control over the way the fault is returned.
 |
| Fault Return |
In case of
a SOAP fault the <detail> element now has a structured sub-element instead
of CDATA. The sub-element is based on the (XML) type of the modeled fault as
defined in the WSDL. That implies you can now use a simple XPath expression to
get to the detail.fault.faultCode where the “fault” is like I modeled it in
the WSDL. In case of REST you can propagate the actual HTTP status code of the
back-end service, instead of a 500.
In the SOAP
Integration example below I still do not have the original fault code in there,
but when the back-end service would return a fault in a format I can rely upon,
I could use an XPath function combination of substring-after() and
substring-before() to get to the back-end fault code. For the sake of example,
I did not take that effort.
 |
| SOAP Fault Return |
Below how I can make it behave in case of a REST service. Notice how I now actually have it return a 404 Not Found, which is the fault code from the back-end service. How nice is that!
 |
| REST Fault Return |
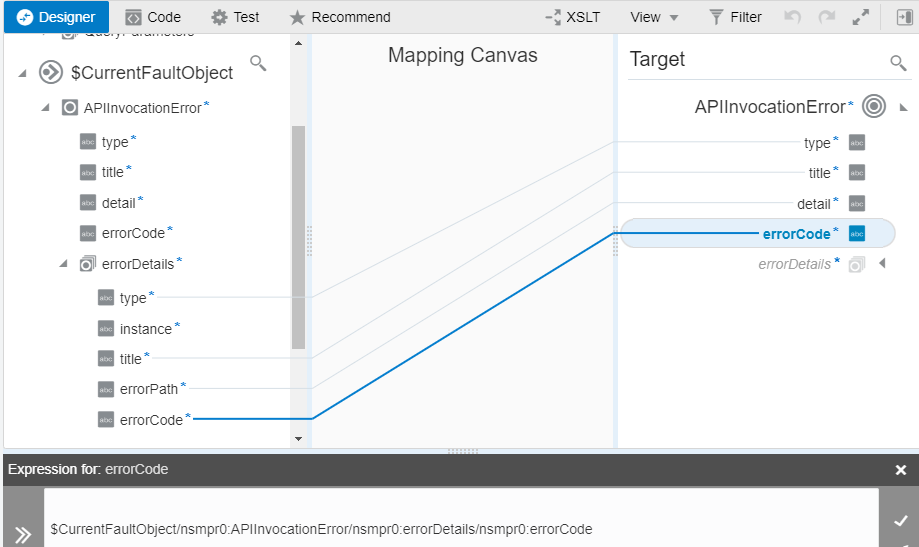
The trick is to map the elements of the errorDetails for the APIInvocationError (instead of the top-level ones):
 |
| Mapping APIInvocationError |
Use Cases: The uses cases for Fault Return are the same as for Throw New Fault. You want to use Fault Return instead if you want the SOAP fault to be more structured or when you want the REST fault to return the original HTTP status code. I expect this will be the case in most situations.
| Best practice | When handling a fault from a back-end service consider using the Fault Return as this offers the same functionality as Rethrow Fault and Throw New Fault but provides more control over the fault returned to the consumer. Most importantly, the modelled fault from the WSDL serves as a “wrapper” to return any fault from the back-end service in a consistent way to the consumer of the Integration, making that it can handle faults in the simplest way.
It also makes the integration instance show as "Succeeded", which strictly speaking is correct as the integration did what it had to do and only passed on the fault message of the back-end service (don't blame the messenger). Faults that happened somewhere else do not unnecessarily draw the attention of OIC Operations.
|
Catching an Integration Fault in a Structured Process
To handle a fault with a service call from a Structured Process you have two options:
- Use Fault Policies.
- Catch faults using a Boundary Error event.
The first is the default and is configured by keeping the “Use Fault Policies” checkbox checked when activating the process. This will result in OIC doing a few retries after which the process instance errors and is being put in a recoverable state. The way to handle that is by going to the Workspace and use the Alter Flow option to recover. In this article I will not further discuss this, maybe some other time.
For the second option you add one or more Boundary Error events to a service call and disable the usage of fault policies, otherwise those events are ignored. When adding a Boundary Event, you have the options:
- Catch a specific Business Exception
- Catch a specific System Exception
- Catch all Business Exceptions (excluding the first two)
- Catch all System Exceptions (also excluding the first two)
Reason to catch a specific Business or System Exception (instead of “catch-all”) is that you may want to handle one differently than another, plus that the payload of a specific exception has specific information that both catch-all options typically lacks.
The following picture shows the popup with the Business Faults I can choose from in my sample application. It also shows the checkbox to Catch all Business Exceptions and Catch all System Exceptions which both can be checked at the same time:
 |
Catching specific Business Exception
|
To catch a specific System Exception, you check the “Show System Faults” checkbox. In the example below the RemoteFault is pointed out. In practice the RemoteFault appears to be the system fault type in most, if not all cases when calling an OIC SOAP Integration (I have yet to come by a counter example). In case of a REST Integration this turns out to be the APIInvocationError.