Special thanks to Greg Mally of the Oracle A-Team for his valuable input.
- It gives you maximum control over the way the fault is returned to the consumer. For example, only with Fault Return will you be able to return the HTTP 4xx or 5xx status code from the back-end service as-is to the consumer of a REST Integration.
- With that it allows you to wrap the fault from the back-end services in one single type of fault thrown to the consumer, making fault handling by the consumer as simple as possible. For example, in case of a modeled SOAP Fault returned to a Structured Process, it now suffices to add one single Boundary Error Event for the modeled fault to handle all business faults in the process.
- On the Monitoring tab the integration instance that handled the fault from the back-end service is itself flagged as “Succeeded” (instead of “Errored”), which strictly speaking is correct as the integration did what it had to do (don’t blame the messenger). After all, the actual fault happened in the back-end service. So instead of unnecessarily alarming the operator of OIC (which caused no issue), Operations should look at either the consumer or the back-end service to find out what went wrong.
Fault Types
A distinction can be made between business faults and system faults where the first refers to a fault explicitly thrown from the business logic. In case of SOAP, business faults are called modeled faults as they are modeled in the WSDL as a "fault" element. In case of REST there is a similarity with the difference between HTTP 4xx client errors and 5xx server errors, although it cannot be compared 100%. For reasons of completeness: according to the W3C specifications a SOAP fault must be sent with an HTTP 500 error code.For the remainder I will use the term modeled fault for both the modeled SOAP fault as well as any REST HTTP 4xx error code, and system fault for the un-modeled SOAP fault and any REST HTTP 5xx status code.
Modeled faults normally come from a back-end service, for example to indicate that it has been called with invalid data (like order with status “paid” cannot be changed). In some cases, you may want to add a modeled fault to the WSDL of the SOAP Integration itself. As discussed hereafter, you do so when implementing fault encapsulation.
System faults are technical faults that for example occur when the back-end service is not available or times out, or when a mapping fails due to a programming error. System faults therefore can come from both the back-end service or are raised by the integration itself.
Fault Handlers
 |
Fault Handlers per type of fault
|
| Best practice | To have more control over and specifically access to the context of the fault, you best put an Invoke activity in a Scope to which you can add a Fault Handler when needed. In case of complex Integrations with many invokes, another advantage of using Scopes is that you can collapse them to get a clearer view of the overall logic of the flow of the integration. |
As is explained hereafter, you cannot pass on the original fault as thrown by the back-end service. It will always be wrapped in some other fault. Therefore:
| Best practice | Use a Fault Handler for each individual fault that can be thrown in the scope, as this gives you the most specific information about the fault. |
Ways to Throw Faults
There are 4 ways to configure how an integration throws a fault:- Do nothing
- Rethrow Fault
- Throw New Fault
- Fault Return
Do Nothing
 |
No handling
|
As there is no strict standard for it, different back-end systems may have significant differences in the way they throw faults, using different (names of) elements, providing a different level of detail. For this reason, in case of a SOAP fault a SOAP Integration will have the original fault details wrapped in CDATA, as shown below. More on this hereafter.
 |
Original fault from back-end service
|
 |
| Fault rethrown by Integration |
Rethrow Fault
 |
| Rethrow Fault |
Throw New Fault
 |
| Throw New Fault |
 |
| New SOAP fault |
 |
| New REST Fault |
Fault Return
 |
| Fault Return |
In case of a SOAP fault the <detail> element now has a structured sub-element instead of CDATA. The sub-element is based on the (XML) type of the modeled fault as defined in the WSDL. That implies you can now use a simple XPath expression to get to the detail.fault.faultCode where the “fault” is like I modeled it in the WSDL. In case of REST you can propagate the actual HTTP status code of the back-end service, instead of a 500.
In the SOAP
Integration example below I still do not have the original fault code in there,
but when the back-end service would return a fault in a format I can rely upon,
I could use an XPath function combination of substring-after() and
substring-before() to get to the back-end fault code. For the sake of example,
I did not take that effort.
 |
| SOAP Fault Return |
 |
| REST Fault Return |
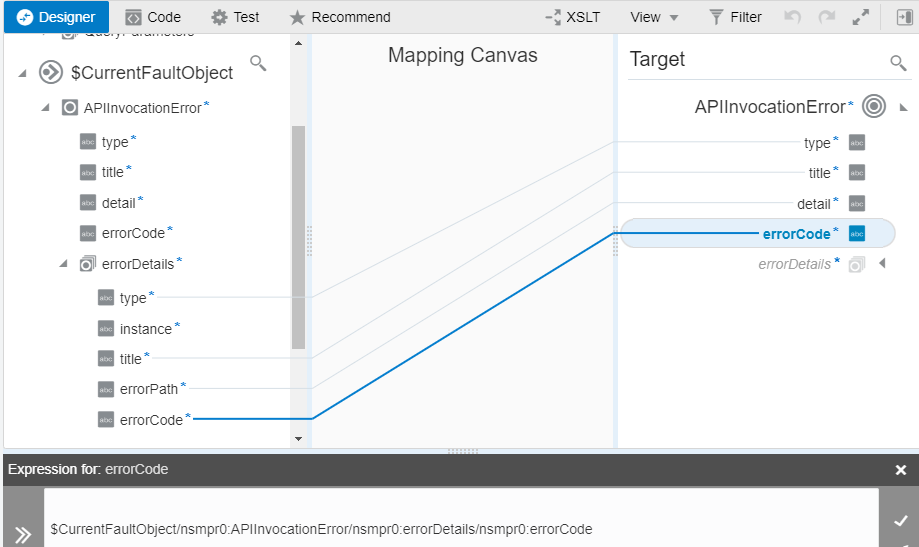 |
| Mapping APIInvocationError |
| Best practice | When handling a fault from a back-end service consider using the Fault Return as this offers the same functionality as Rethrow Fault and Throw New Fault but provides more control over the fault returned to the consumer. Most importantly, the modelled fault from the WSDL serves as a “wrapper” to return any fault from the back-end service in a consistent way to the consumer of the Integration, making that it can handle faults in the simplest way. It also makes the integration instance show as "Succeeded", which strictly speaking is correct as the integration did what it had to do and only passed on the fault message of the back-end service (don't blame the messenger). Faults that happened somewhere else do not unnecessarily draw the attention of OIC Operations. |
Catching an Integration Fault in a Structured Process
To handle a fault with a service call from a Structured Process you have two options:- Use Fault Policies.
- Catch faults using a Boundary Error event.
For the second option you add one or more Boundary Error events to a service call and disable the usage of fault policies, otherwise those events are ignored. When adding a Boundary Event, you have the options:
- Catch a specific Business Exception
- Catch a specific System Exception
- Catch all Business Exceptions (excluding the first two)
- Catch all System Exceptions (also excluding the first two)
The following picture shows the popup with the Business Faults I can choose from in my sample application. It also shows the checkbox to Catch all Business Exceptions and Catch all System Exceptions which both can be checked at the same time:
 |
Catching specific Business Exception
|
To catch a specific System Exception, you check the “Show System Faults” checkbox. In the example below the RemoteFault is pointed out. In practice the RemoteFault appears to be the system fault type in most, if not all cases when calling an OIC SOAP Integration (I have yet to come by a counter example). In case of a REST Integration this turns out to be the APIInvocationError.
 |
Catch specific exception |
In case of a catch-all the elements you can use are as below. From experience I can tell you that only the errorInfo contains some useful information, the faultName and faultNamespace typically do not help with explaining the cause.


In case of a modelled SOAP fault I have all fields available as I modelled them in the WSDL:

This illustrates the rationale for the last-mentioned best practice to use Fault Return as an exception wrapper to ease fault handling by your consumer.

2 comments:
Thanks Jan! Really appreciate you spending the time to document this. It has really helped me out.
Really nice details. Thank tou.
Post a Comment