In the following article I explain why you should implement a Structured to Structured Process call as synchronous when you need that call to be recoverable in case of an issue.
To call a Structured Process (that is initiated by a Message Start event) from another one, there are 2 ways to do so (actually there are 3 if you count in the Micro Process feature but that is a variation of one of these, I suspect the first):
- Using the /ic/api/process/v1/processes API
- Using the WSDL of the called process
I typically do the latter, as I find it to be simpler than using the API because importing the WSDL involves an automatic import of the XSD schema containing the request definition. Copy & paste of the WSDL URL and you're done and when the interface changes, all I have to do is re-import the schema (in contrast, when using the API I have to manually figure out the proper JSON sample).
However, whichever way you use both concern a web service based interface, which you can configure to invoke in one of two ways:
- As Fire-and-Forget
- As synchronous (request/response)
Question is which one to use? The answer is simple: use synchronous in case there is no callback and you want to be sure the invocation either succeeds or can be recovered when it fails. If you don't care, use Fire-and-Forget. Read on to find out why.
First let me point out the Fire-and-Forget Enterprise Integration Pattern. As it will tell you, in case of Fire-and-Forget error handling is not possible and you would need some Guaranteed Delivery mechanism to prevent the risk of losing messages. Mind that web service based invocation is not message based (which would involve using a Message Channel and with that typically an Invalid Message Channel to capture bad messages). So, in case of Fire-and-Forget there will be the risk of running into a non-recoverable error (hence the conclusion). OIC has no "magic feature" supporting recovery from failed invocations to Fire-and-Forget web services. And mind you, this is consistent with the pattern.
Note: in case of (asynchronous) process-to-process invocation with callback you do have a recovery point, which will be on the the callback. When using a Send/Receive pair of activities you can put a boundaryTimer Catch event on the Receive activity that you can model to go into a recovery flow when it does not receive a response in time. This article is about the situation when there is no such callback.
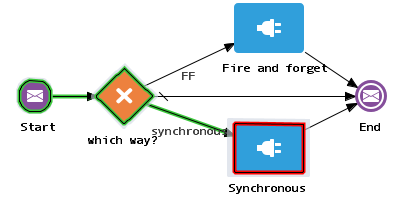
So when can this fail, and what are the consequences? To illustrate I have created a parent Process application that calls one of two child Process applications where one is Fire-and-Forget and the other synchronous. There are 2 different situations that can lead to an issue:
- The child process is not available
- The child process receives an invalid request it cannot process
To simulate the second I connected the two processes and then modified the child process to have an extra element in its interface that I map at the start event. If not provided, the mapping will result in a selectionFailure (NPE).
The Fire-and-Forget child process looks as follows. I have put a user activity in it as a simple means to make it stop after receiving the message.

The synchronous child process looks as follows. I have put a Message Throw event with name "Response" right after the Start event. The Respond event is configured as a synchronous response to the Start event.

Invalid Request
Now what happens when I let the parent call these child processes with the invalid request? The following shows the instances as you can find them in Workspace -> Processes:
What you see here is that in case of Fire-and-Forget the following happens:
- The parent with title "SM FF versus Sync [non-recoverable]" succeeds and get the Completed state
- The child with title "SM Child FF" errored
The flow of the parent looks like this:

The flow of the child looks like this:

As you can see the instance of the child rolled back to the start event and is not recoverable. The only option is Abort. As the parent instance is in state Completed, you also cannot recover from there (obviously).
What you see regarding the synchronous invocation, is the following:
- The child with title "SM Child Sync" fails and it retries 2 times
- After 3 tries the parent gets the Errored state
The parent is now in state "Recoverable" and its flow looks like this:
I can now recover the parent using Alter Flow and add the missing element that the child failed on:

The parent now succeeds:

And a new instance of the child process that initially failed is now in state In Progress (the bottom one initially fails, the top one now succeeds):
Child not Available
The above covers the question what happens in case the child process receives an invalid request. Now what happens when it is not available? There can be 3 situations that would make it so:
- The child has been Shut Down
- The child has been Retired
- The child has been Deactivated (undeployed)
The following shows what happens:

As you can see, in case of Fire-and-Forget the parent only gets in an errored, retriable state when the child is deactivated. In all other cases the parent succeeds. In contrast, in case of a synchronous invocation, the parent fails in all three situations.
Conclusion
So conclusion is that for process to process invocation without callback you must make the invocation synchronous if you want to be able to recover in case of an issue. In case of Fire-and-Forget this is not possible (as the enterprise pattern argues).